
AI is leaving the cloud. Models that needed an NVIDIA H100 cluster two years ago run on a laptop today. Models that needed a laptop now run on a phone. Apple Intelligence ships on a billion devices. Humanoid robots run foundation models onboard. Compute is moving from data centers to devices, fast.
The cloud has been the ceiling on what AI can become. For years it was the only place AI could live: training needed a data center, serving needed a GPU cluster. Every assumption underneath modern AI was built around that constraint - the model, the user data, the decisions, the audit trail, all in the cloud.
That arrangement does not work for what AI is becoming. Surgical robots, autonomous vehicles, factory floors, and personal agents do not tolerate a round trip to a data center, do not benefit from sending sensitive data to servers they do not own, and cannot get accountability from an audit log that depends on a network connection.
The model is the easy part. The hard part is everything around it.
A model running alone on a device is a demo. To turn it into a product, you need a data layer underneath: the data the model reads and writes, the rules about who can see those reads and writes, the proof of what the model did, and the sync that keeps it all coherent across devices.
Most teams building edge AI have not figured this out. They moved the model and left everything else in the cloud. The inference runs locally; the data still flies to AWS. The architecture is half-translated, and the half that did not move is the half that matters most.
Edge-first, cloud-last is the data architecture that frees AI from the cloud. It rests on three inversions of how cloud-first software gets made: compute moves to the data, rules travel with the data, and trust starts at the edges.
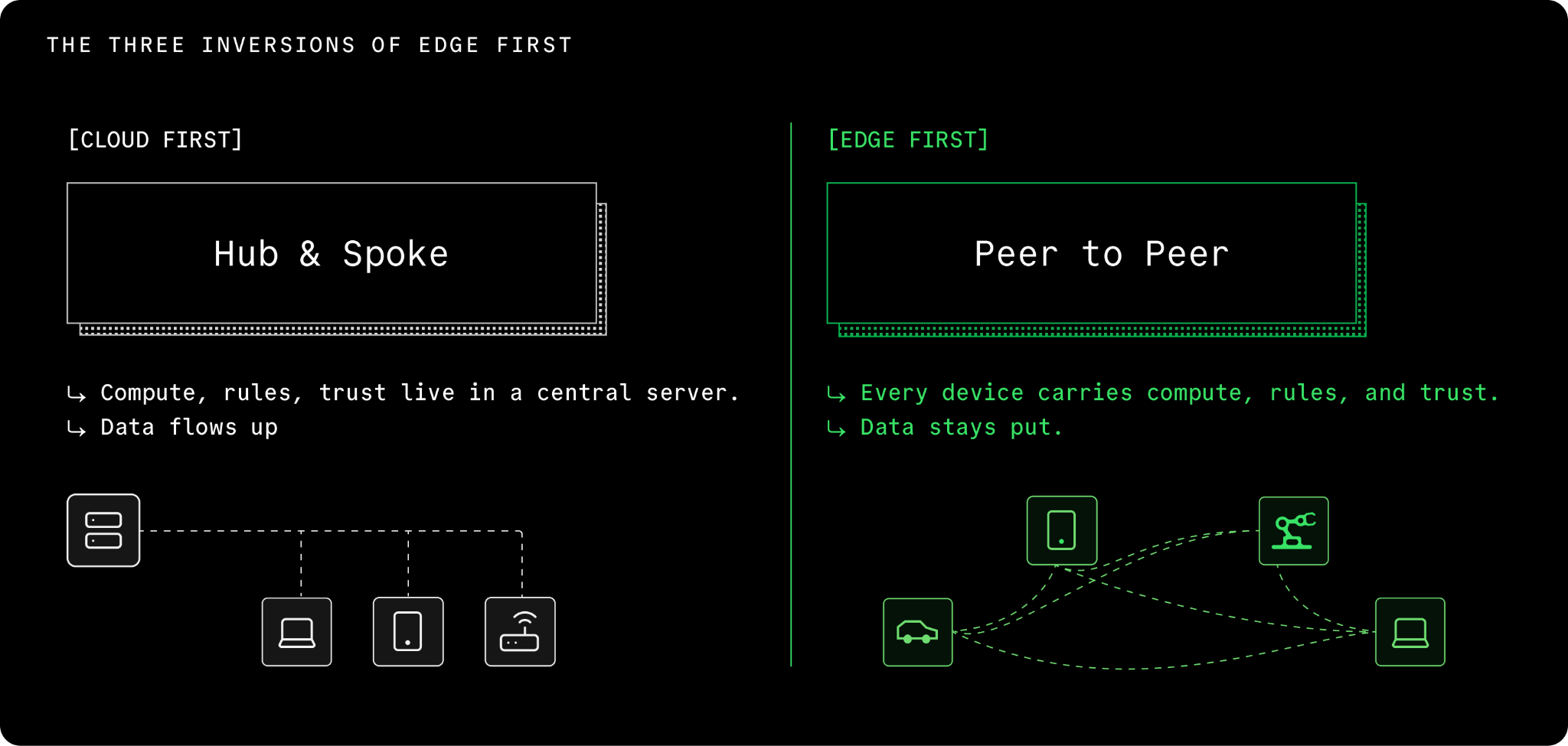
The first inversion: services come to the data
In cloud-first, data travels. Your app captures something, sends it to a server, and the result comes back. The data travels because the compute lives in the cloud - and the compute lives in the cloud because that is where you put it.
Watch this play out. A surgical robot reads sensor data. The data leaves the building, travels to AWS, a model decides whether the next motion is safe, the decision travels back. If the network blinks, the robot stops. The decision about whether to cut a person open is gated on a round trip to Virginia.
Edge-first inverts it. Compute moves to wherever the data already lives. The model runs on the robot. The sensor data never leaves the building. Data movement becomes deliberate instead of reflexive.
For AI, this is the foundational unlock. If your model is local but it has to call a cloud API to load the user's history or write its outputs back to a server, you are still cloud-first wearing a different hat. When the model and the data live in the same place, AI gets to do things it could not do before: real-time inference at robot speed, voice and vision processing that never leaves the user's hands, agents that work with full personal context without that context ever leaving the device.
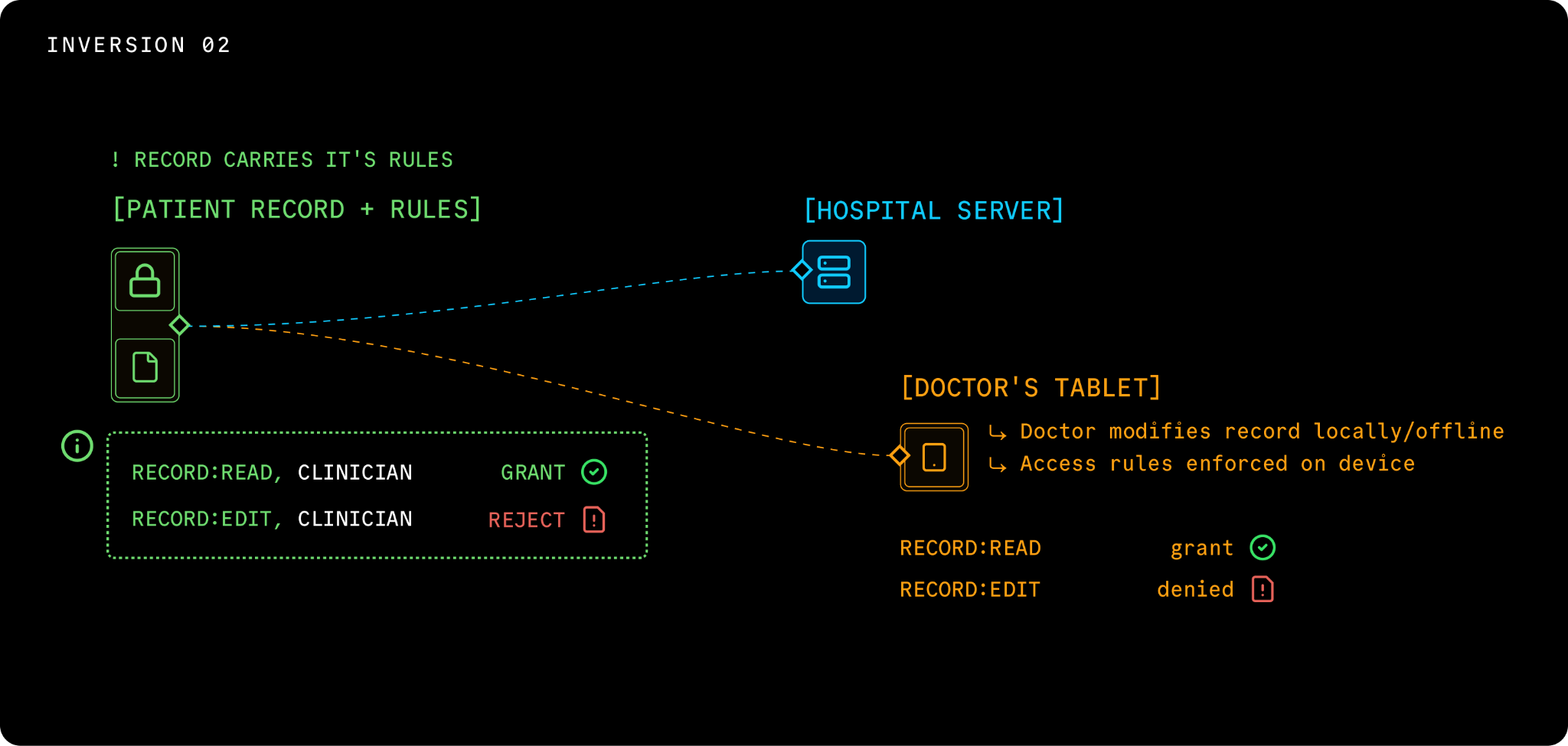
The second inversion: guardrails travel with the data
Access control in cloud-first is a service problem. The database has its rules. The API has its rules. The vector store has its rules. The model serving layer has its rules. Each one is built separately, each one can be wrong separately, each one can be breached separately. Multiply that across every microservice in a modern AI stack and you get a permission surface no one fully understands.
Now add an AI agent. An agent reads, writes, calls services, and chains decisions. In cloud-first, each action hits a different permission boundary enforced by whichever service the agent called. The agent's scope is the accidental union of those checks. Nobody designed it.
When the agent runs on a device with no network, the model breaks entirely. There is no service to ask.
Edge-first attaches the rules to the data itself. Take a patient record moving between systems. In cloud-first, the rules live everywhere except the record - in the EHR, the lab system, the research database, the AI diagnostic agent's API gateway. Reconciling them is a project. Auditing them is a harder one.
In edge-first, the record carries its rules. When it lands on a doctor's tablet, the rules land too. An AI agent on that tablet sees the rules before it sees the data, and cannot opt out. The rules are structural.
This is what unlocks agentic AI at scale. Once rules live with data, agents can act across systems, devices, and networks without a permission rewrite at every step. The data is the gatekeeper. That is the architecture that lets agents leave the demo and become the product.
The third inversion: trust originates at the edges
In cloud-first, the server decides who to trust. The client asks. The server checks. The server grants. From OAuth to SAML, every authentication system follows this pattern. There is a single point where trust is decided - which means a single point that can be compromised, coerced, or unreachable.
For agents, three questions come up immediately. Who is this agent? What is it allowed to do? How do you prove what it actually did? In cloud-first, all three answers depend on a server. If the server is unreachable, the agent freezes or runs blind. If it is compromised, all three answers can be rewritten after the fact.
Edge-first makes trust cryptographic and verifiable at the source. The agent has its own identity. Its permissions are encoded in credentials it carries. Every read, write, and decision is signed and checkable. The audit trail travels with the agent.
An AI agent on your phone can prove to a regulator, an auditor, or to you that it followed the rules - without anyone needing to ask a service that may or may not still exist. Trust originates with the parties in the conversation, not with a platform vouching for them.
Why now
The AI itself changed first. Agents do not request - they act. An architecture built for request-response cannot govern software that acts on its own.
The hardware changed too. A current-generation phone runs models that needed a GPU cluster five years ago. The neural processing units now shipping in phones, tablets, and laptops were purpose-built for inference workloads that used to be data-center only.
The economics changed. At AI scale - continuous video, sensor streams, constant context loading - egress costs are real and latency is a product problem. A model that takes 200ms to round-trip to AWS cannot be in the loop of a robot that needs to react in 20.
Privacy is now regulated. GDPR, CCPA, the EU AI Act, and the EU Cyber Resilience Act are all responses to what happens when data flows to a single party. The cloud-first AI stack was built for a world where none of this was enforced. That world is over.
What edge-first is not
Edge-first is not anti-cloud. The cloud is excellent at coordination across large user bases, heavy training workloads, and long-term storage. Edge-first demotes the cloud from default to deliberate. Use it when you need it.
Edge-first is not just embedded sensors. It applies to phones, laptops, browsers, robots, vehicles, medical devices, and AI agents. Anywhere software runs and data is generated, the same three inversions apply.
The most ambitious things AI is supposed to do - agents that act, robots that decide, personal intelligence that respects privacy, systems that prove what they did - none of them work on a cloud-first data layer. They were never going to.
At Source, we are building [DefraDB](https://source.network/defradb), the database built for edge-first software. If this framing landed for you, there is more at https://source.network.
